




I. Définition▲
I-A. Qu'est-ce qu'un contour ?▲
Comme nous l'avons vu lors de la troisième partie intitulée « Introduction aux Différents Types de Segmentation » un Contour est une zone de transition filiforme entre deux zones homogènes de l'image, appelées Régions, conformément au schéma de la figure n° 1 (a). Pour comprendre ces notions, il est intéressant d'étudier le profil de l'intensité de l'image dans la direction perpendiculaire au contour (cf. figure n° 1 (b)).

I-B. Exemple de contour▲
Plutôt que d'intuiter ce que pourrait être un profil entre deux zones homogènes, ce que font certains auteurs en définissant un contour comme une marche d'escalier parfaite entre deux régions, nous allons l'observer.
L'image du bureau se prête particulièrement bien à la visualisation des contours. En effet, les contours verticaux présents sont mis en évidence sur le profil horizontal présenté lors de la seconde partie intitulée « Visualisation des Images et Opérateurs Simples », pour visualiser la notion de bruit dans les images. Plusieurs exemples de contours sont visualisés sur la figure n° 2 (a), puis agrandis (b).
Tout d'abord un contour n'est pas une marche d'escalier parfaite. La transition s'étale sur plusieurs pixels(1). Une modélisation plus fidèle est présentée Figure n° 2 (b).

Nous avons utilisé le vocabulaire classique, tel qu'il est utilisé dans la communauté scientifique, et qui n'est malheureusement pas assez précis. En effet, un contour est une information globale de l'image, c'est une zone de transition filiforme certes, mais d'extension notable. Or, nous venons de parler d'un profil, perpendiculaire au contour en un point, donc en toute rigueur nous aurions dû parler d'un point de contour ! Un contour est un ensemble ordonné, plus exactement une liste de points de contour.
I-C. Dérivée première et dérivée seconde▲
La détection du contour va s'effectuer en détectant l'ensemble de ses points. Ceci nous amène à nous poser la question : « Comment détecter le point de contour P correspondant au contour sur un profil perpendiculaire au contour ? »
La réponse est simple : le point P est le point dont la tangente au profil est la plus importante, donc où la pente est maximale (cf. Figure n° 3).
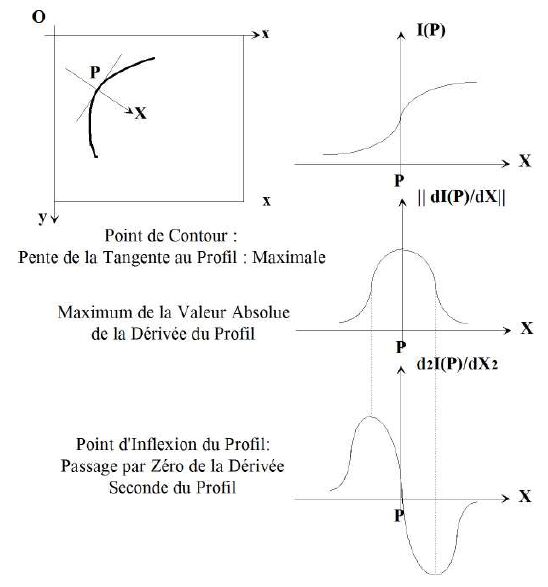
Le profil |dI/dX| en fonction de X (direction perpendiculaire au contour) est obtenu par dérivation du profil I(X). La dérivée est la pente de la tangente. Pour X < 0 la pente est nulle. Lorsque l'on se déplace dans le sens de X croissants, elle augmente, devient maximale pour X = 0, décroit ensuite pour s'annuler.
Le profil d2I / dX2 en fonction de X, c'est-à-dire la dérivée seconde du profil I(X), est obtenu par dérivation du profil |dI / dX| en fonction de X. La pente de la tangente au profil dI/dX est d'abord positive. Elle croit, passe par un maximum, puis décroit, passe par zéro en X = 0, passe ensuite par un minimum, puis recroit pour s'annuler.
Ainsi, comme le montre la Figure n° 3 le point de contour P du profil correspond au maximum de la valeur absolue de la dérivée première du profil, et au passage par zéro de la dérivée seconde, appelé Point d'Inflexion(2).
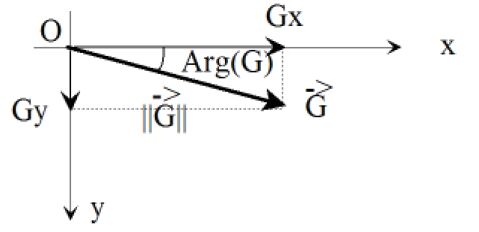
À deux dimensions, car l'image I(x,y) est bidimensionnelle, la dérivée première est un vecteur : le Gradient et la dérivée seconde un scalaire : le Laplacien. Les expressions en coordonnées rectangulaires (x,y) des opérateurs gradient et laplacien sont rappelées ci-dessous(3).
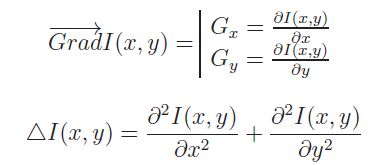
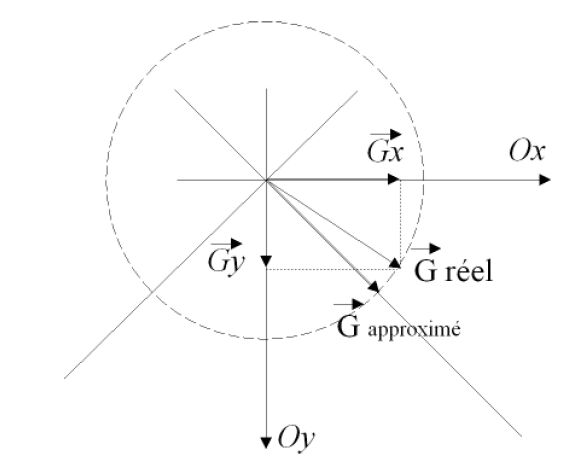
Le gradient est un vecteur, il est, comme nous le verrons, obtenu à partir de ses projections Gx et Gy sur les axes de coordonnées Ox et Oy de l'image. Or l'information intéressante est (cf. Figure n° 4) :
- sa norme qui est le reflet de l'amplitude du contour, ou du contraste entre les deux régions ;
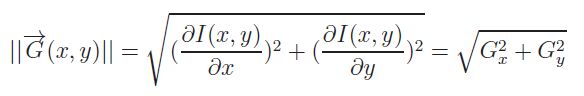
- sa direction qui est à π/2 près celle du contour.
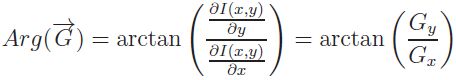
II. Opérateur de détection des gradients▲
Tout ceci est théorique. Passons maintenant à la pratique.
II-A. Choix pédagogique▲
Nombreuses sont les méthodes proposées pour détecter les gradients. Nous en distinguons trois grands types :
- à partir des différences locales : telle que la méthode de Roberts, des années 60, proposée en 1965 utilisant le voisinage 2 x 2, ou le gradient radial de formule ci-dessous :
-
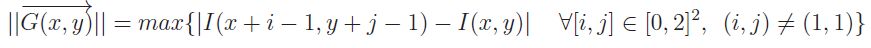 à partir d'un lissage moyen ou gaussien sur trois lignes (respectivement trois colonnes) des différences locales horizontales (respectivement verticales), ce qui revient à utiliser des filtres linéaires sur le voisinage 3 x 3 centré. Ce sont des filtres à réponse impulsionnelle finie RIF. Ces méthodes ont été proposées dans les années 70 ;
à partir d'un lissage moyen ou gaussien sur trois lignes (respectivement trois colonnes) des différences locales horizontales (respectivement verticales), ce qui revient à utiliser des filtres linéaires sur le voisinage 3 x 3 centré. Ce sont des filtres à réponse impulsionnelle finie RIF. Ces méthodes ont été proposées dans les années 70 ;
- à partir d'un lissage exponentiel, ce qui revient à un voisinage limité à l'image entière par l'utilisation des filtres récursifs. Ces méthodes ont été proposées dans les années 80.
Nous allons développer les méthodes du second type uniquement. En effet :
- d'une part, les méthodes du premier type, très simples, produisent des résultats trop bruités ;
- d'autre part, les méthodes du troisième type sont trop complexes pour être abordées dans cet article. Je ne voudrais pas réaliser dans ce livre le nième plagiat de la thèse remarquable de JF Canny, ou de l'article de R.Deriche comme je l'ai vu dans certains ouvrages ! Celui-ci m'est personnel ! De plus, par rapport aux méthodes du second type, les résultats obtenus sont certes un peu de meilleure qualité, mais sans rapport avec la complexité théorique et le temps de calcul supplémentaire ;
- enfin, les méthodes du second type offrent le meilleur compromis complexité(4)/rapidité d'exécution (propriété fondamentale en robotique mobile et autonome) et qualité des résultats obtenus.
Nous allons donc présenter trois méthodes : Prewitt (1970), Sobel (1978) et Kirsh à quatre directions (1971). Puis nous les comparerons au niveau de leurs algorithmes, puis de leurs résultats.
II-B. Un exemple simple de détection de contours▲
Attention à l'imprécision dans le langage déjà évoquée, puisqu'il s'agit de points de contour et non de contours !
Comme nous le montrons dans notre ouvrage, le masque Mh horizontal de Prewitt suivant détecte les différences locales horizontales, ou gradients horizontaux, c'est-à-dire les contours verticaux. L'orientation de l'axe est de la gauche vers la droite.
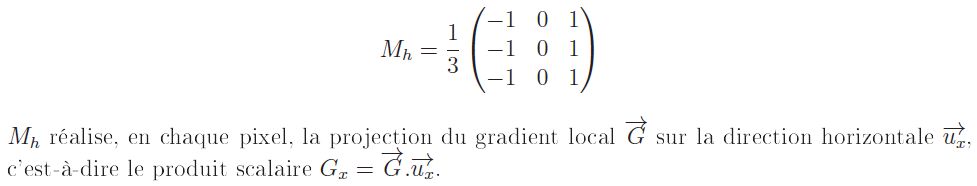
Pour obtenir Mv le masque vertical de Prewitt, il suffit de faire subir une rotation d'un angle de π/2 au masque horizontal Mh, soit :
kitxmlcodelatexdvpM_v = \frac{1}{3} \begin{pmatrix} -1 & -1 & -1 \\ 0 & 0 & 0 \\ 1 & 1 & 1 \\ \end{pmatrix}finkitxmlcodelatexdvpL'orientation de l'axe est de haut en bas. De la même manière, Mv réalise, en chaque pixel, la projection du gradient local sur la direction verticale, c'est-à-dire le produit scalaire :
kitxmlcodelatexdvpG_y = \overrightarrow{G} . \overrightarrow{u_y}finkitxmlcodelatexdvpII-C. Opérateurs de Prewitt et Sobel▲
Le principe des méthodes proposées par Prewitt en 1970 et par Sobel en 1978 est identique. Il consiste à projeter le gradient présent en chaque pixel de l'image selon les deux axes de l'image : Ox et Oy en utilisant les deux vecteurs unitaires de ces axes. Ces deux projections, ainsi que la norme du gradient sont :

L'argument ou l'orientation du Gradient est :
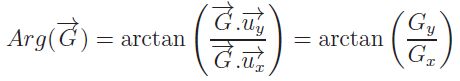
Les masques de convolution associés aux vecteurs unitaires selon les axes Ox et Oy de l'image pour les opérateurs de Prewitt et de Sobel peuvent être regroupés selon un même formalisme :
Masques de Prewitt et Sobel
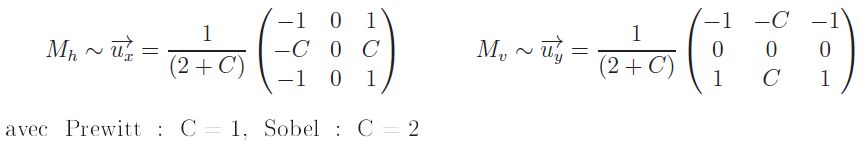
Sauf pour quelques utilisations particulières telles que la transformée de Hough pour détecter les centres de cercles, l'argument du gradient ne sert que pour l'étape d'Affinage dont le but est d'obtenir des (points de) contours(5) d'un pixel d'épaisseur. Dans cette utilisation, l'argument est utilisé pour déterminer les deux pixels voisins dans la direction du gradient, dans le voisinage 3 x 3 centré. Ainsi, une discrétisation de l'argument du gradient selon les directions des huit voisins, (cf. Figure n° 5) ou selon les quatre directions horizontale, verticale et les deux obliques (cf. Figure n° 6) s'avère être suffisante.
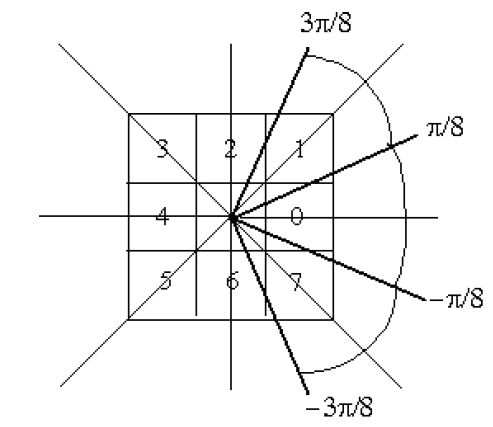
La discrétisation de l'argument du gradient, revient à faire une rotation du gradient sur l'une des directions des huit voisins du voisinage 3 x 3 centré, ou sur l'une des quatre directions : horizontale, verticale, et les deux obliques, comme le montre la Figure n° 6. Le gradient ainsi obtenu est donc une approximation du gradient réel.
L'algorithme du calcul de la norme et l'argument du gradient, ainsi que la différence entre les opérateurs de Prewitt et de Sobel font l'objet des exercices d'approfondissement, dans la Partie II de notre ouvrage. Il en est de même pour la quasi-totalité des opérateurs présentés.
Les opérateurs de Prewitt et Sobel sont obtenus respectivement par les commandes EdGradientPrewitt, et EdGradientSobel. Les codes source des interfaces sont contenus dans les fichiers EdGradientPrewitt.c et EdGradientSobel.c. Les codes source des opérateurs sont respectivement contenus dans les fichiers EdLibGradientPrewitt.c et EdLibGradientSobel.c.
II-D. Opérateur de Kirsh à quatre directions▲
Le principe de l'algorithme de Kirsh à quatre directions, proposé en 1971, consiste en un premier temps à projeter le vecteur gradient selon quatre directions : Ox, Oy, et les deux bissectrices à +/-45°, en utilisant les quatre vecteurs unitaires correspondants.
Puis, le gradient obtenu, comme approximation du gradient réel, est le vecteur projeté le plus proche, comme l'explique la Figure n° 7.

Soit les quatre vecteurs projetés. On obtient le gradient approximé de la manière suivante :

Les masques de convolution associés aux vecteurs unitaires pour l'algorithme de Kirsh à quatre directions sont les suivants :
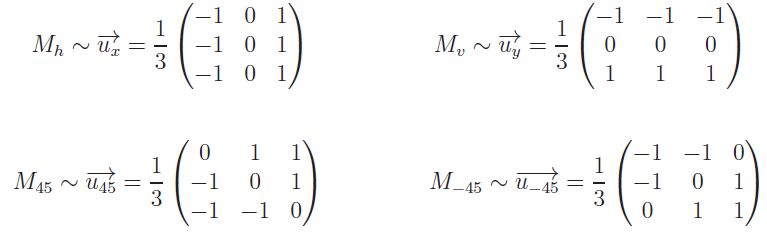
Les masques de convolution M45 et M-45 sont obtenus à partir de Mh et Mv par une rotation de π/4. L'opérateur de Kirsh à quatre directions est obtenu par la commande EdGradientKirsh4. Le code source de l'interface est contenu dans le fichier EdGradientKirsh4.c, et celui de l'opérateur dans le fichier EdLibGradientKirsh4.c.
II-E. Comparaison des opérateurs : Prewitt, Sobel - Kirch▲
II-E-1. Niveau de l'algorithme▲
Comparons l'algorithme des deux types de méthodes :
- Prewitt et Sobel d'une part ;
- Kirsh d'autre part.
Les méthodes de Prewitt et Sobel projettent le gradient sur deux axes Ox et Oy à l'aide de deux masques de convolution, puis effectuent une transformation de coordonnées : rectangulaires - polaires. Cette dernière étape en version non optimisée est réalisée par des calculs en nombres réels (de type « double » en Langage C / C++), et utilise les fonctions mathématiques Racine carrée ( sqrt() ) et Arc Tangente (arctan()). L'approximation est réalisée lors de la discrétisation de la norme en fonction de quatre ou huit directions.
En revanche, la méthode de Kirsh projette le gradient sur quatre axes : Ox, Oy et les deux bissectrices, à l'aide de quatre masques de convolution, puis effectue un simple choix de la projection la plus semblable, qui en constitue l'approximation.
Dans les années 70(6), il était très pénalisant de faire des calculs en nombres réels. Il était donc plus pénalisant temporellement d'effectuer la transformation de coordonnées rectangulaire - polaire que les deux nouvelles projections sur les deux bissectrices. Aujourd'hui, tout dépend du niveau d'optimisation de l'implantation, et du processeur sur lequel sont implantés les opérateurs. Le tableau ci-dessous résume ces différences.

Au niveau de l'argument du gradient la discrétisation revient à :
- effectuer une rotation du gradient selon l'une des quatre directions horizontale, verticale et les deux obliques, la plus proche, pour les méthodes de Prewitt et Sobel ;
- projeter le gradient sur l'une de ces quatre directions, la plus proche, pour la méthode de Kirsch.
II-E-2. Niveau des résultats : qualité de la segmentation▲
Les résultats de l'image de la norme du gradient sont bien conformes à notre attente (cf. Figure n° 9). En effet, la norme du gradient est d'autant plus importante que la transition entre les deux zones l'une plus claire et l'autre plus foncée est importante. Les parties claires sur l'image de la norme des gradients correspondent bien aux contours de l'image.
Les résultats de l'image de la norme du gradient sont identiques à l'œil pour les trois méthodes présentées : Prewitt, Sobel et Kirsch. Nous allons confronter leur résultat à l'issue de l'étape suivante, c'est-à-dire après l'affinage des contours (cf. Figure n° 11).

La figure n° 10 représente la norme de la projection du gradient selon les quatre directions du filtre de Kirsh :
- les axes de coordonnées : ux (b) et uy (c) ;
- les deux bissectrices : u45 (d) et u-45 (e) ;
ainsi que le résultat de l'opérateur : la norme maximum (f).

On constate que les contours verticaux et horizontaux génèrent respectivement des gradients horizontaux et verticaux (gradient et contours sont à π/2), mais également sur les deux directions obliques.

Les trois opérateurs Prewitt, Sobel et Kirsh présentent des résultats corrects à l'issue de l'étape d'Affinage, cf. figure n° 10. Les (points de)contours de l'image sont correctement extraits. Le fil du téléphone sur la partie gauche de l'image, pratiquement invisible à l'œil, est quasiment extrait en totalité par les trois opérateurs.
Comme pour l'image de la norme des gradients, l'image des points de contours obtenue après l'étape d'affinage ne nous permet pas de classer ces trois opérateurs, tant les résultats sont similaires.
II-F. Détails d'implantation : notion d'optimisation▲
Nous présentons ici une implantation avec un premier niveau d'Optimisation Temporelle par Regroupement des Calculs Locaux, et Optimisation de ces Calculs. Il existe d'autres niveaux d'optimisation de l'implantation des opérateurs, tels que l'Optimisation de l'Accès aux Pixels que nous détaillerons au cours d'une seconde série d'articles.
Le calcul du gradient par les méthodes de Prewitt et Sobel comporte trois étapes distinctes (cf. Figure n° 12 (a)) :
- le calcul de la projection du gradient G sur ux, soit Gx ;
- le calcul de la projection du gradient G sur uy, soit Gy ;
- la transformation de coordonnées : rectangulaire polaire.
Il n'y a pas d'ordre à respecter entre les deux premières étapes. En revanche, les deux premières étapes doivent être réalisées pour effectuer la transformation de coordonnées.
Le calcul du gradient par la méthode de Kirsh à quatre directions comporte cinq étapes distinctes (cf. Figure n° 13 (a)) :
- le calcul de la projection du gradient G sur ux, soit Gx ;
- le calcul de la projection du gradient G sur uy, soit Gy ;
- le calcul de la projection du gradient G sur u45, soit G45 ;
- le calcul de la projection du gradient G sur u-45, soit G-45 ;
- le choix de la meilleure approximation.
De manière similaire, il n'y a pas d'ordre à respecter entre les quatre premières étapes. En revanche, les quatre premières étapes doivent être réalisées pour effectuer le choix de la meilleure approximation.
Un informaticien, soucieux de la réutilisabilité de son code, programmerait une procédure de convolution, qui serait appliquée successivement :
- deux fois dans l'implantation des méthodes de Prewitt et Sobel, pour le calcul des deux projections du gradient, avant la transformation de coordonnées ;
- quatre fois dans l'implantation de la méthode de Kirsh à quatre directions, avant le choix de la meilleure approximation.
Le nombre de balayages d'images nécessaires serait alors :
-
pour les méthodes de Prewitt et Sobel :
- quatre pour les calculs des deux gradients (une image d'entrée et une image de sortie pour chaque convolution),
- quatre pour la transformée Rectangulaire - Polaire (deux images en entrée : les deux projections des gradients, et deux en sortie : la norme et l'argument) ;
-
pour la méthode de Kirsh :
- huit pour les calculs des quatre gradients (idem Prewitt - Sobel),
- six pour le choix de la meilleure approximation (quatre images en entrée : les quatre projections des gradients, et deux en sortie : la norme et l'argument).
Mais, il est possible de regrouper les calculs locaux (c'est-à-dire de les effectuer en même temps pour chaque pixel) :
- des trois étapes pour les méthodes de Prewitt et Sobel (cf. Figure n° 12 (b)) ;
- des cinq étapes pour la méthode de Kirsh (cf. Figure n° 13 (a)).
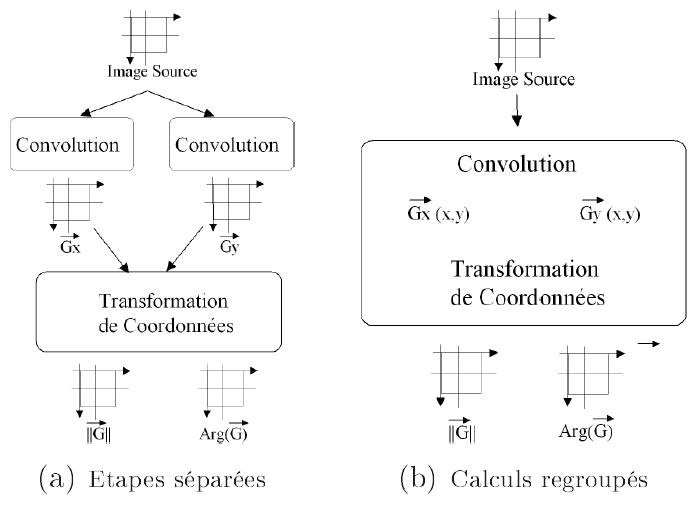

Le nombre de balayages d'image nécessaires a considérablement diminué, il devient de trois, quelle que soit la méthode considérée :
- un pour l'image d'entrée ;
- deux pour les images de sortie : norme et argument.
Sachant qu'un balayage de l'image « prend du temps », on comprendra l'intérêt d'en diminuer le nombre.
Ces optimisations n'ont aucune influence sur la qualité des résultats : les calculs restent rigoureusement les mêmes, en revanche le facteur d'accélération est important comme le souligne le tableau ci-dessous pour l'opérateur de Kirsh. Nous comparons ici(7) :
- une version comportant quatre convolutions indépendantes suivies de la transformation de coordonnées : celle choisie par l'informaticien soucieux de la réutilisabilité de son code. Le calcul des adresses des pixels n'est pas optimisé ;
- avec une version dans laquelle les cinq étapes précédentes ont été regroupées. Comme pour la version précédente, le calcul des adresses des pixels n'est pas optimisé(8).

Nous avons également remarqué, « benchmarks » à l'appui, que nous perdrions environ 30 % de temps de calcul supplémentaire, si au lieu de calculer l'adresse du pixel puis d'en lire ou d'en écrire le contenu, nous utilisions des fonctions du style get_pixel() pour lire la valeur du pixel et put_pixel() pour l'écrire. Attention pour les fans de l'encapsulation en C++ de laisser le libre accès aux pixels de l'image !
Autant le temps de calcul dépend du processeur sur lequel les « benchmarks » sont effectués : fréquence d'horloge, taille du cache, etc. En revanche, les ratios obtenus sont constants, sauf s'il y a une modification architecturale importante entre les deux processeurs, ce qui a lieu lorsque l'on change de génération (par exemple pour la gamme Intel 286, 386, 486, et Pentium).
III. Le laplacien▲
III-A. Théorie▲
À une dimension, comme nous l'avons mentionné figure n° 3, le contour se traduit également par un passage par zéro de la dérivée seconde. En numérique, nous pouvons définir le signal I(x) puis :

Une approximation numérique du laplacien peut donc être réalisée avec le masque de convolution suivant, somme des deux masques de convolution représentant une approximation numérique des dérivées secondes selon x et y :
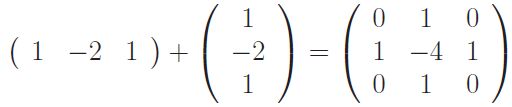
Remarquons que la somme des coefficients du masque étant nulle, sa réponse en zone homogène est nulle également. Ainsi, pour détecter les points de contours, ce n'est pas une égalité à zéro qu'il faut rechercher, mais un passage par zéro.
III-B. Résultats▲
La figure n° 14 présente les résultats du laplacien. Les images (b) et (d) présentent la Polarité du Laplacien c'est-à-dire les valeurs du laplacien :
- positives, supérieures à un seuil donné (seuil de 5 pour l'image (b), 10 pour (d)), représentées en blanc (= 255) ;
- négatives, inférieures à un seuil donné (seuil de -5 pour l'image (b), -10 pour (d)), représentées en gris (= 100) ;
- et proches de zéro (représentées en noir (= 0)).
Les images (c) et (e) présentent les Passages par Zéro recalés sur les valeurs de polarités positives du laplacien, c'est-à-dire les points pour lesquels :
- la valeur du laplacien est positive ;
- il existe un point dans le voisinage 3 x 3 centré de polarité négative.

III-C. Conclusion▲
Comme le montrent les images (c) et (e) de la figure n° 14 avec des seuils de valeurs respectives 5 et 10, les résultats obtenus sont très difficilement exploitables. En effet, pour un seuil de valeur 5, les points de passage par zéro sont bien trop nombreux. Pour une valeur de 10, des points de bruit restent, alors que des points situés sur les contours ont disparu.
Remarque : bien que qualifiée de Méthode de Base pour la détection des contours dans la plupart des ouvrages, il est très difficile d'extraire des contours corrects à partir des points sièges de passage par zéro du laplacien. Certains ouvrages expliquent quand même, à juste titre, qu'une dérivée qui effectue une différence entre valeurs de pixels voisins élimine la valeur moyenne et de ce fait amplifie le bruit. Il est normal qu'une dérivée seconde l'amplifie encore plus.
L'opérateur laplacien est obtenu par la commande EdLaplacian. Le code source de l'interface est contenu dans le fichier EdLaplacian.c, et celui de l'opérateur dans le fichier EdLibLaplacian.c.
IV. Diverses étapes▲
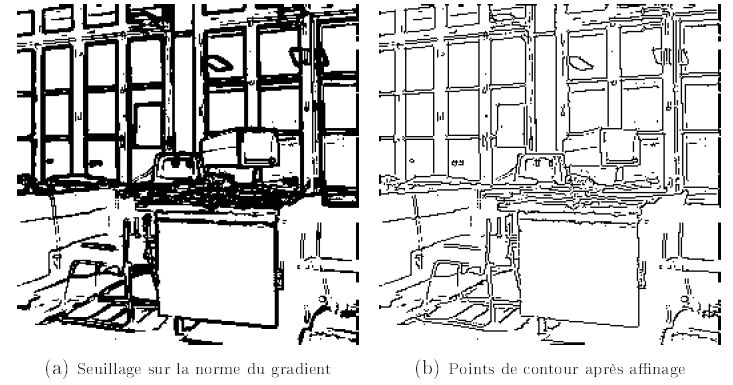
Un contour réel de l'image est normalement bien marqué. Une première sélection des points de contours potentiels peut être effectuée par un simple seuillage sur la norme du gradient. Comme cela est visible figure n° 15 (c), un réglage de la valeur du seuil donnant des résultats parfaits est impossible : il apparaît aussi bien des trous dans les contours(9), par exemple sur le fil du téléphone de la face avant du bureau de gauche, que des contours épais(10), par exemple sur les montants des fenêtres. Le seuillage sur la norme constitue la seconde étape de la détection. La valeur du seuil correctement choisie engendrera nécessairement les deux types de problèmes.
Pour remédier au problème des contours épais, la troisième étape d'Affinage des Contours va consister à ne garder un point de contour que si la norme de son gradient est maximale dans la direction orthogonale au contour, assurant ainsi le caractère filiforme cf. figure n° 15 (d).
Pour remédier au problème des trous dans les contours, la quatrième étape de Prolongation ou de Fermeture des Contours consiste en un premier temps à repérer les extrémités des contours, puis en un second temps en abaissant le seuil de sélection sur la norme du gradient, de suivre le chemin de norme de gradient maximale (« ligne de crête ») issue de l'extrémité. Par exemple, les trous précédemment signalés dans les contours représentant le fil du téléphone, ont disparu cf. figure n° 15 (e).
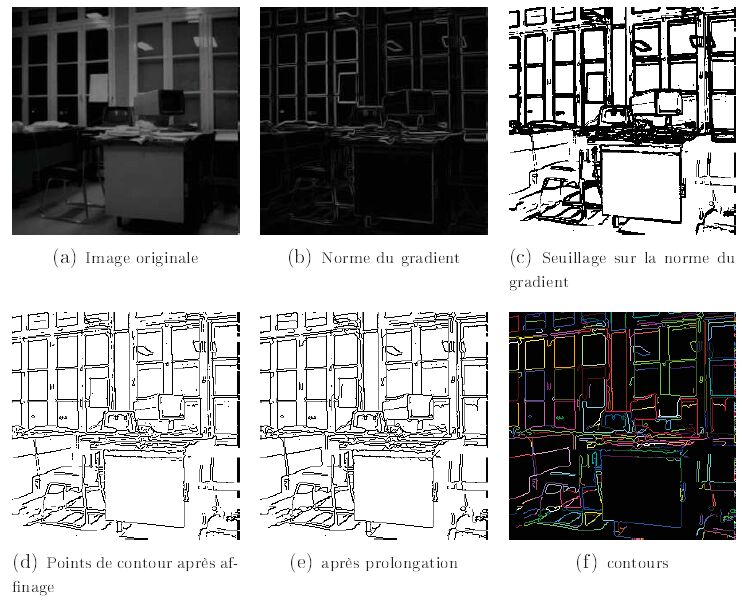
L'information des points de contours ainsi obtenue étant difficilement exploitable, les deux étapes suivantes ont pour objet de la mettre en forme. Ainsi, la cinquième étape a pour but de lier les points de contours les uns aux autres pour former les contours.
Un contour est par définition une liste ordonnée(11) de points de contours. Cette étape est appelée Chaînage des Contours. La figure n° 15 (f) représente l'image des étiquettes des points de contours. Chaque pixel est affecté du numéro du contour auquel il appartient, ou de la valeur zéro s'il n'appartient à aucun contour. Par conséquent, tous les pixels d'un même contour apparaissent de la même couleur dans cette image.
Le contour, comme liste de points de contours n'étant pas plus exploitable, le rôle de la dernière étape est de modéliser le contour ainsi extrait. C'est grâce à cette modélisation que l'on va pouvoir reconnaître les éléments recherchés dans l'image. La modélisation la plus simple est la Ligne Polygonale, soit une ligne composée d'un ensemble de segments de droite jointifs. L'étape prend alors le nom d'Approximation Polygonale. Une telle étape est employée en vision robotique, car dans les environnements humains figurent de nombreux objets rectilignes générant des lignes droites dans les images. En imagerie médicale, où peu de droites figurent, on utilise des approximations plus complexes.
Ainsi, en résumé, les principales étapes d'une segmentation en contour sont les suivantes :
- calcul du gradient local en norme et argument ;
- seuillage sur la norme du gradient ;
- affinage des contours ;
- prolongation des contours ;
- chaînage des contours ;
- approximation des contours.
L'étape de « Seuillage sur la Norme du Gradient » étant un algorithme de seuillage classique détaillé lors du second article, nous ne détaillerons dans la suite que l'étape d'« Affinage des Contours », les étapes suivantes le seront dans la prochaine série d'articles.
En effet, les étapes de « Prolongation ou Fermeture des Contours », de « Chaînage des Contours » et d'« Approximation » sont bien plus complexes, car leurs calculs ne sont plus réguliers : ils sont guidés par le contenu de l'image, c'est-à-dire les données(12).
Remarque
Dans nos recherches en matière de segmentation en contours, nous avons privilégié l'approche précédemment mentionnée, en optimisant l'organisation des six étapes, ramenées à deux, et en proposant plusieurs algorithmes de chaînage, et un algorithme combinant prolongation et chaînage.
Mais, il est possible de procéder autrement. En effet, à l'issue de l'étape d'affinage, il est possible d'obtenir directement la modélisation des contours sous forme de droites, de cercles, ou d'ellipses à l'aide de méthodes généralement basées sur la Transformée de Hough.
Nous avons testé ces méthodes, et des résultats ont été présentés lors du troisième article. Elles se sont révélées très « gourmandes » en temps de calcul, incompatibles avec notre problématique de vision robotique, et notamment d'implantation des opérateurs sur les robots AIBO puis NAO, où la puissance de calcul est très restreinte. La plupart, voire la quasi-totalité des nombreux ouvrages de traitement d'image / vision privilégient cette seconde approche, en oubliant complètement ou ne mentionnant que très succinctement la première.
V. l'Affinage des contours▲
V-A. Position du problème : analyse et principe▲
Le but de l'opérateur d'Affinage des Contours est d'obtenir des (points de) contours d'un pixel d'épaisseur en ne conservant qu'un seul point de contour dans la direction orthogonale au contour.
Sur une image réelle, la transition entre les deux zones homogènes considérées (c'est-à-dire le contour) est rarement « franche ». Le profil n'est pas une marche d'escalier parfaite, et génère donc un gradient de norme non nulle sur plusieurs pixels selon la direction orthogonale au contour (ou selon la direction du gradient) comme cela est montré figure n° 16.
Pour réaliser l'affinage, on ne garde que les pixels sélectionnés par le seuillage sur la norme, dont la norme du gradient est :
« Maximale Locale (i.e. dans le voisinage 3 x 3 centré) Directionnelle
dans la direction du gradient, c'est-à-dire la direction orthogonale au contour. »
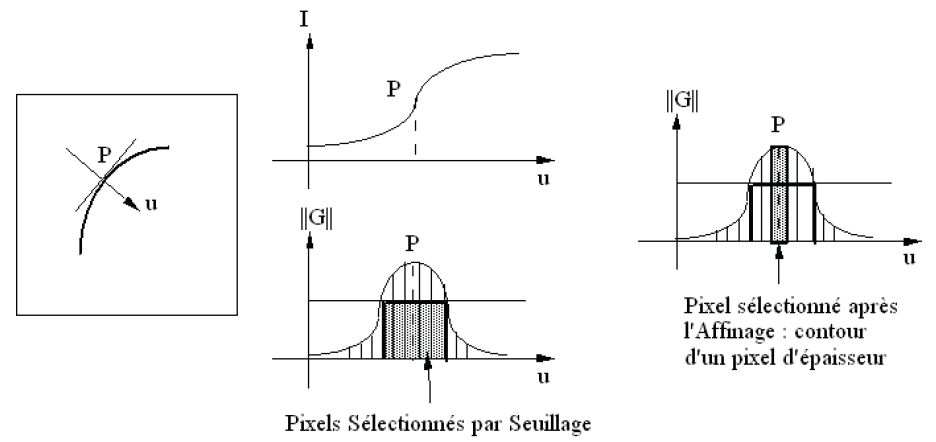
Ainsi, le pixel courant, sélectionné par l'étape de seuillage sur la norme doit être comparé à ses deux voisins V1 et V2 dans la direction du gradient(13). Ces deux pixels voisins sont diamétralement opposés par rapport au pixel courant. L'un est dans le passé, appelons-le V1, l'autre dans le futur, appelons-le V2 (cf figure n° 17).
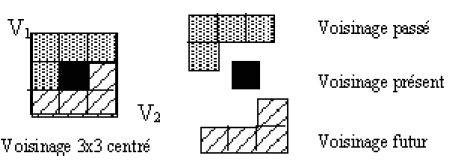
Le pixel courant est de contour après l'étape d'affinage si et seulement si la norme de son gradient est supérieure à la norme du gradient de ses deux voisins V1 et V2.
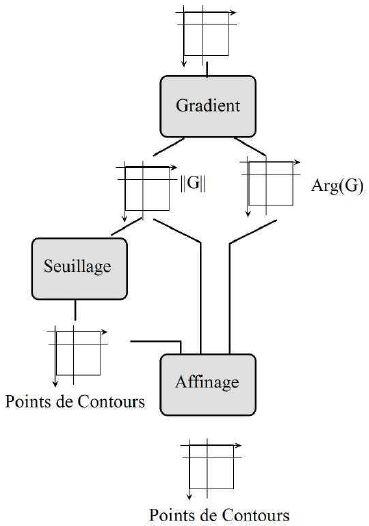
L'algorithme d'affinage nécessite de disposer en entrée de trois images :
- les images de la norme et de l'argument du gradient ;
- l'image des points de contour, obtenue par seuillage sur la norme du gradient.
La sortie de l'algorithme est l'image des points de contour, modifiée par l'algorithme lui-même(14). L'enchaînement des trois étapes, notamment en termes d'entrées / sortie est présenté figure n° 18.
Retrouvez cet enchaînement dans l'interface, contenue dans le fichier EdGradientThinning.c.
V-B. Algorithme de l'affinage à deux voisins▲
L'algorithme est proposé ci-dessous :

L'obtention de points de contour à partir d'un opérateur de gradient (Prewitt, Sobel, ou Kirsh à quatre directions) suivi d'un opérateur d'affinage est obtenu par la commande EdGradientThinning. Le code source de l'interface est contenu dans le fichier EdGradientThinning.c, et celui de l'opérateur d'affinage dans les fichiers EdLibThinning.c et EdLibEdgeUtilities.c.
V-C. Résultats▲
Les résultats obtenus par l'opérateur d'affinage à deux voisins sont présentés figure n° 19. Les contours obtenus(15) sont bien d'une épaisseur d'un pixel. Ce résultat est d'autant plus remarquable dans les zones de contours épais, c'est-à-dire de transition importante, notamment entre les armatures et les carreaux des fenêtres. Les contours faiblement marqués, et à trous, comme le fil du téléphone ne sont pas altérés par l'étape d'affinage.
VI. Conclusion▲
Lors de cette cinquième partie, intitulée Segmentation en Contours,nous avons présenté la notion de contour, ainsi que les différentes étapes constituant une segmentation en contours. Ensuite le principe des trois premières : le calcul du gradient, le seuillage sur la norme du gradient, et l'affinage a été détaillé.
Avec cette cinquième partie du cours intitulé : « Les Bases du Traitement d'Image et de la Vision Industrielle et Robotique » nous avons terminé la partie théorique qui nous a présenté un certain nombre d'opérateurs dits de bas niveau :
- histogrammes, opérateurs de visualisation ;
- opérateurs de seuillage ;
- opérateurs linéaires agissant sur un voisinage 3x3 centré ;
- opérateurs de lissage d'image ;
- opérateurs de morphologie mathématique ;
- opérateurs de calcul de gradients, et d'affinage des contours.
La sixième et dernière partie, intitulée l'Environnement Logiciel de Traitement d'Image EdEnviTI : Principe et Programmation, sera plus pratique. Elle présentera l'environnement, et son utilisation pour la programmation d'opérateurs. Ensuite, à vous de programmer par vous-même les opérateurs présentés et de comparer votre solution aux codes de la bibliothèque EdVision, fournis sur le site « Developpez.com ». Puis pourquoi pas développer vos propres opérateurs ?