




I. Préambule ▲
Ce cours, le troisième de la série de six est volontairement court, car il présente des notions bien plus complexes qui ne font pas partie d'une Introduction ou des Bases du Traitement d'Image, à niveau BAC + 3.
Ces notions seront traitées dans une série d'articles suivante, à niveau Ingénieur ou Master, mais toujours dans le même esprit de simplification et de détails. Nous présenterons, comme dans cette première série, les algorithmes des opérateurs plus compliqués. Les codes source seront fournis sur le site web www.developpez.com.
Nous présentons néanmoins, au cours de cette première série d'articles :
- une chaîne complète de segmentation : article n° 4,
- le principe et les principales étapes d'une segmentation en contours, article n° 5, car les opérateurs sont relativement simples.
Ce cours a pour objectif de répondre succinctement à certaines questions qu'il est légitime de se poser à ce stade de l'apprentissage du traitement d'image :
- Quelle information extraire de l'image, et sous quelle forme ?
- Comment utiliser cette information pour réaliser une application ?
pour comprendre la philosophie de cette science.
Enfin, les résultats présentés dans cet article sont :
- soit personnels, provenant d'opérateurs publiés ou non ;
- soit ont été obtenus par mes quatre doctorants, avec lesquels j'ai eu plaisir à travailler :
François Le Coat(1), Aymeric de Cabrol(2), Rabih Al Nachar(3) et Mathieu Pouzet(4) .
EFFIDENCE est une société de Clermont-Ferrand, experte en robotique et qui naturellement utilise entre autres la vision pour automatiser un certain nombre de plates-formes robotiques : militaires et civiles dans les domaines du transport et de l'agriculture (cf. figure n° 1) : www.effidence.com.

II. Objectif de la segmentation▲
Les opérateurs de Bas Niveau, tels que ceux que nous venons d'étudier fournissent une image comme résultat. Celle-ci est destinée :
- soit à être interprétée par un opérateur humain, par exemple une image médicale lissée est interprétée par un médecin ;
- soit à être utilisée par un traitement de niveau supérieur : intermédiaire ou haut. Le traitement de bas niveau joue alors le rôle d'une des premières étapes d'un traitement plus complexe.
Les opérateurs de Niveau Intermédiaire fournissent des marques distinctes dans l'image : les Primitives ou Caractéristiques images, affectées de leurs Attributs c'est-à-dire des valeurs numériques. Ceux de Haut Niveau fournissent comme résultat une Décision.
Ainsi, en fonction de l'application envisagée, l'information extraite peut prendre des formes diverses et variées :
- sur le plan de la sémantique (contenu) : de « j'ai extrait une zone de l'image de telle intensité en imagerie N&B ou de telle couleur en imagerie RVB » ou « un segment de droite » (i.e. les coordonnées de ses deux points extrémité), c'est-à-dire une information purement numérique ou de niveau intermédiaire, à « j'ai identifié tel panneau routier, par exemple un sens unique, et je dois le signaler au conducteur » ou « la pièce examinée est conforme », information d'un niveau symbolique(5), en relation avec la scène observée et qui va générer une action ;
-
sur le plan de la représentation : celle-ci peut être :
- dans l'image (espace 2D : segmentation statique) : une forme obtenue par une approximation(6) de son contour ou par son intérieur de niveau de gris, de texture ou de couleur constante,
- dans la séquence d'images (espace 2D + t : segmentation dynamique) : telle marque distinctive (ou cible) est suivie au cours de la séquence d'images, donc dans le temps,
- dans la scène (espace 3D) : par exemple : pour l'application RoboCup Soccer, le robot voit la balle à 2 m dans telle direction, et pour une application de navigation, le robot a repéré tel obstacle à tel endroit de son environnement sur sa trajectoire, donc va le contourner.
Dans les deux derniers exemples ci-dessus, l'information utile comporte conjointement les deux niveaux :
- Symbolique : la balle, ou le panneau ont été détectés : une action doit être enclenchée ;
- Numérique : la distance et la direction dans l'espace 3D sont des informations capitales pour réaliser l'action.
Segmenter une image consiste à extraire cette information. Lorsque l'on parle de segmentation en points d'intérêt, contours, régions, mouvement, couleur et stéréo vision(7), on parle en général des algorithmes permettant d'extraire l'information à Niveau Intermédiaire : c'est-à-dire des attributs numériques. Ceux-ci seront les entrées des procédures de plus haut niveau de Filtrage sur Attributs permettant la Reconnaissance de Forme et l'Identification d'Objets Recherchés.
Pour les segmentations statiques : points d'intérêt, contours, régions, l'hypothèse suivante est posée :
- les points d'intérêt et contours correspondent à la projection dans l'image des bords externes ou internes (dans le cadre d'un objet comportant plusieurs zones de niveau de gris ou de couleur) des objets,
- les régions correspondent, au contraire, à la projection de zones homogènes en niveau de gris ou en couleur des objets.
Nous montrerons dans la seconde série d'articles que l'extension à la couleur ou plus généralement au multispectral(8), des segmentations en N&B ou monospectral peut se faire simplement.
III. « Seuillage » suivi d'une décomposition en composantes connexes▲
Une procédure composée d'un seuillage(9) suivi d'une décomposition en composantes connexes est une segmentation statique. Elle consiste à sélectionner les points des zones d'intérêt de l'image, puis à les regrouper en taches ou composantes connexes.
Les informations numériques extraites sont de nature :
-
géométrique : permettant la localisation dans l'image :
- surface,
- centre de gravité,
- boîte englobante ;
-
photométrique : permettant l'identification :
- niveau, ou couleur.
Cette segmentation fait l'objet de l'article suivant.
IV. Points d'intérêt▲
Une segmentation en points d'intérêt est également une segmentation statique. Un certain nombre d'opérateurs ont été proposés dans la littérature : des plus simples : Moravec, Harris, aux plus complexes : SUSAN acronyme de « Smallest Univalue Segment Assimilating Nucleus », SIFT « Scale Invariant Feature Detector » de D.Lowe et SURF « Speeded Up Robust Feature Detector ».

Figure n° 2 : Comparaison des détections de points d'intérêt (Rabih Al Nachar).
Ces points d'intérêt sont généralement obtenus directement à partir de l'examen de leur voisinage (plus ou moins complexe) dans l'image. Certains auteurs tels que R. Al Nachar proposent comme points d'intérêt des coins ou sommets de lignes polygonales.
Un contour est approximé par une ligne polygonale, c'est-à-dire un ensemble de segments de droite jointifs. Un coin est la jonction entre deux segments successifs.
Dans son mémoire de doctorat, R. Al Nachar compare les résultats de son détecteur (ligne n° 2 de la figure n° 2) de « coins » obtenus à partir des contours, aux détecteurs de la littérature : SUSAN (3), Harris (4) , Harris-Laplace (5), FAST (6) et SURF (7) sur une image réelle prise de différents points de vue (1). Cette image réelle n'est pas anodine. En effet, nous utilisons de telles marques distinctives dans le cadre de nos recherches en robotique mobile, pour recaler la navigation des robots, dans un environnement coopératif.
La figure n° 3 présente les résultats du détecteur de coins sur des images de la littérature.

La Primitive point d'intérêt est très utilisée dans de nombreuses applications(10), citons : le recalage d'images, la création de panoramas, la reconnaissance d'objets, le suivi de cibles et même la reconnaissance de caractères déformés (CAPTCHA) ou manuscrits (cf. figure n° 4).
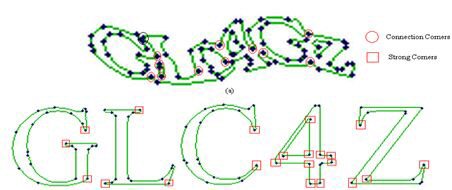
V. Contours▲
La Primitive Contour fait l'objet du cinquième article. Les contours correspondent aux bords externes et internes des objets. Ils sont filiformes c'est-à-dire d'épaisseur un pixel. En fonction des applications, plusieurs niveaux de « finition » peuvent être employés :
- les points de contours : par exemple pour colorier automatiquement l'intérieur des formes ;
- les contours, c'est-à-dire une liste ordonnée(11) de points de contour connexes ;
-
une modélisation des contours :
- sous forme de segments de droites : on parlera d'approximation polygonale,
- sous forme plus globale : de droites, de cercles, d'ellipses, par exemple en utilisant la Transformée de Hough.

La figure n° 5 présente les résultats(12) de :
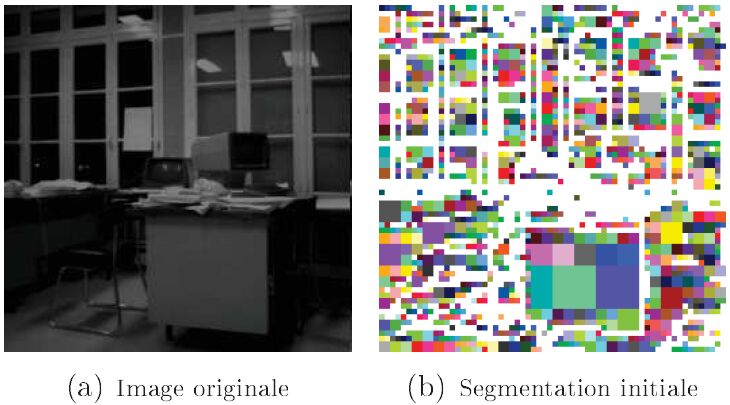
- (a) : approximation polygonale, sur l'image du bureau ;
- (b) : détection de droites par transformée de Hough, pour une application de conduite assistée / conduite autonome. Remarquons que l'on obtient ici les directions principales et non l'ensemble des différentes droites ;
- (c) : détection de cercles par transformée de Hough, pour une application de détection de panneaux circulaires ;
- (d) : détection d'ellipses par transformée de Hough, pour une application de détection de visages.
La figure n° 6 présente les résultats de l'approximation polygonale pour l'application RoboCup. Ce traitement, temporellement optimisé(13) tourne à cadence vidéo sur le robot NAO, à partir d'images YUV comprimées au format 4.2.2.

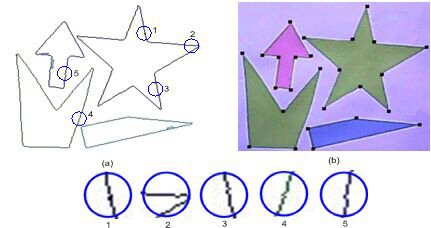
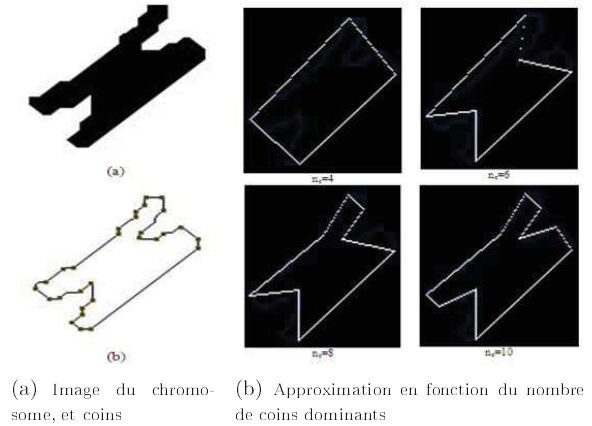
La figure n° 7 présente les résultats de l'approximation polygonale et l'influence du bruit sur la détection des segments de droite et des coins les joignant. R. Al Nachar proposa ensuite une méthode permettant de classer les coins par « force » : les Coins Dominants et ainsi de pouvoir contrôler leur nombre, ce qui revient à contrôler le nombre de segments de droite de l'approximation polygonale. La méthode permet, par exemple, de mieux reconnaître des objets à des échelles différentes. La figure n° 8 présente l'approximation polygonale résultante en fonction du nombre de coins dominants ou de segments de droite.
VI. Régions▲
VI-A. Segmentation classique▲
Le but de la Segmentation en Régions va être de regrouper entre eux les pixels connexes de même niveau de gris pour une segmentation N&B ou mono spectrale, ou de même « couleur » pour une segmentation couleur dans l'espace colorimétrique RVB, YUV ou autres, ou multispectral. Un exemple de résultat de segmentation en régions, sur l'image du bureau est présenté figure n° 9. Nous avons proposé l'algorithme en 1989.

Les algorithmes de segmentation en régions sont généralement composés de plusieurs étapes successives. En effet, il est très difficile, voire quasiment impossible, de regrouper correctement les pixels pour former des régions en une seule procédure, car les régions sont généralement homogènes au centre et le sont de moins en moins plus on s'en éloigne. L'idée est de partir des zones homogènes puis de relâcher progressivement les contraintes. Ceci nous amène à regrouper des points entre eux en un premier temps, puis des régions ensuite, ce qui ne peut pas se faire avec le même algorithme.
Comme le montre Pavlidis, la segmentation initiale peut être prise de deux manières différentes, ainsi qu'à partir d'une combinaison de ces deux manières :
- à partir de l'image entière, et en la découpant récursivement jusqu'à obtenir des régions initiales suffisamment homogènes (algorithme de Découpage ou Split) ;
- à partir des pixels de l'image, que l'on regroupe ou fusionne les uns aux autres (algorithme de Fusion ou Merge) ;
- à partir d'un regroupement quelconque, en utilisant successivement le découpage, puis la fusion. Une telle procédure est intéressante, lorsque l'on dispose d'une segmentation proche, ce qui est le cas lorsque l'on segmente une séquence d'images, où l'on dispose des résultats de la segmentation de l'image précédente pour segmenter l'image courante.
La figure n° 10 présente les résultats de la segmentation initiale en régions de Pavlidis, sur l'image du bureau, obtenue à l'aide de la procédure de découpage itératif que nous arrêtons de manière à obtenir des régions de taille supérieure ou égale à 4 x 4. La programmation de cet algorithme fait l'objet d'un « travaux pratiques » de 4 h, l'algorithme ayant été détaillé en cours magistral, au niveau Master.
Aymeric De Cabrol et moi-même avons proposé l'algorithme dont les résultats sont présentés figure n° 11. C'est un algorithme rapide et peu coûteux en temps de calcul. Il a été implanté sur les robots AIBO et NAO. Il assure une fusion des régions en six étapes :
- trois étapes de Regroupement Pyramidal : les points d'une grille (1 sur 3 pour les lignes et 1 sur 3 pour les colonnes) regroupent les pixels de leur voisinage 3 x 3, puis de manière similaire les Régions 3 x 3 germes (1/3 sur les lignes et sur les colonnes) regroupent les régions de leur voisinage pour former une région de taille 9 x 9. Enfin, similairement, les régions 9 x 9 germes regroupent les régions de leur voisinage pour former des régions 27 x 27.
- trois étapes de Regroupement Isotrope, Couronne par Couronne ou Flot de Données : d'abord les régions 27 x 27 entre elles, puis les régions 9 x 9 sont ajoutées, et enfin les régions 3 x 3.

VI-B. Segmentation coopérative▲
Les contours étant la projection des bords des objets et les régions leur intérieur, les résultats des segmentations en contours et en régions devraient présenter idéalement les propriétés suivantes :
- les régions sont l'intérieur des contours fermés ;
- les contours sont les frontières des régions.
En pratique, les segmentations étant obtenues par des mécanismes de regroupement sur deux différents types de points
- pour les contours : les points, sièges de différences d'intensité dans leur voisinage,
- pour les régions : les points, sièges d'homogénéité locale (ou dans le voisinage),
les résultats obtenus par les deux segmentations sont notablement différents dans les parties difficiles des images réelles, généralement non parfaites. C'est le cas par exemple dans les zones peu contrastées, car mal éclairées.
Pour éviter ce problème, il est possible d'effectuer conjointement les deux segmentations en contours et en régions, les résultats intermédiaires de l'une permettant le contrôle de l'autre. Ayant constaté en 1989 que
- les contours étaient plus précis que les frontières de régions,
- mais que certains contours (de faible extension) étaient liés au bruit et n'apportaient aucune information,
nous avons proposé une méthode de segmentation coopérative, dont les caractéristiques sont les suivantes. Une segmentation en contours permet de guider efficacement la croissance des régions. Ensuite, les contours de petite taille, non situés sur une frontière de régions sont éliminés.
VII. Mouvement▲
VII-A. Caractéristique image▲
Le Mouvement est une caractéristique image(14) issue d'une séquence d'images, au même titre que les points d'intérêt, les contours et les régions sont des caractéristiques statiques issues d'une image.
L'intérêt d'une caractéristique image est de pouvoir générer une action.
C'est parce que l'on peut extraire la forme d'un objet grâce
- à son contour externe,
- à ses régions,
que l'on peut le saisir. De manière automatique, le contour peut être extrait grâce à la primitive point d'intérêt, où les points sont régulièrement répartis sur le contour, ou grâce à la primitive contour. Les régions sont extraites grâce à la primitive région. Il est possible de prendre l'objet à l'aide d'un bras de robot, par exemple.
Mettre en évidence, la caractéristique mouvement est plus complexe. Heureusement la nature vient à notre aide. Observons attentivement la figure n° 11. La raie(15) en bas de l'image, camouflée, car de même texture que le sable est difficilement visible sur une image fixe. En revanche, visualisons la vidéo de son déplacement : elle devient alors parfaitement visible, grâce à l'information de mouvement.
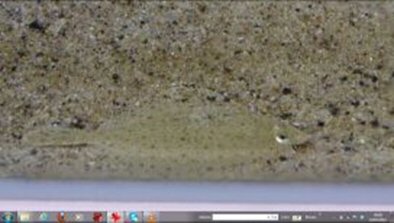
VII-B. Segmentation en mouvement▲
Le but de la Segmentation en Mouvement va dépendre de l'application. Il va consister à étudier la Déformation entre deux images pouvant être :
- successives d'une même séquence ;
- entre l'image courante de la séquence et une image de référence, ou un arrière-plan dépourvu d'objet mobile ;
- entre deux images prises à des instants notablement différents, de la même scène sous deux angles de prise de vue distincts ;
- entre deux images prises au même instant de deux caméras différentes, etc.
L'information à extraire peut permettre en fonction de l'application :
- la détermination d'un mouvement dense, c'est-à-dire du mouvement de chaque pixel d'une image à l'autre ;
- la modélisation de ce précédent mouvement : par exemple dans l'hypothèse d'un mouvement plan ;
- la détermination de la transformation affine composée d'une translation, d'une rotation et d'un changement d'échelle ;
- la détermination du mouvement local des objets mobiles, permettant un suivi dans le temps ;
- la détermination de la forme 3D (« Shape from Motion »).
Toujours, en fonction de l'application, les techniques employées peuvent être de complexité très différente :
- de la simple différence d'image, permettant d'obtenir les objets mobiles, dans le cas d'une caméra fixe (cf. figure n°13(16)) ;
- à la détermination du mouvement du fond de manière à le recaler avant la détection des objets mobiles, dans le cas d'une caméra mobile dont le mouvement peut être de grande amplitude(17) (cf. figure n° 17).
Des résultats obtenus par différence d'images sont présentés figure n° 13. Il s'agit d'une différence dite du premier ordre entre l'image courante et l'image de référence (ici la première de la séquence). La différence est effectuée pixel à pixel. La visualisation est la suivante : si la différence est suffisante (supérieure à un seuil), l'intensité du pixel dans l'image courante est recopiée. Le véhicule en mouvement est bien détecté, ainsi que quelques pixels de bruit dans le fond.

VII-C. Classification des méthodes de segmentation en mouvement▲
Une propriété des caractéristiques images est de pouvoir permuter(18).
C'est-à-dire que l'on peut obtenir une caractéristique image à partir d'une autre.
Entre caractéristiques statiques :
- un contour peut être considéré comme la frontière d'une région, et la région l'intérieur d'un contour ;
- de même, un point d'intérêt peut être vu comme un point anguleux du contour, et le contour comme un ensemble de points d'intérêt successifs reliés entre eux.
Cette commutation est également possible entre les caractéristiques statique et dynamique. Elle nous permet de classer les méthodes de Segmentation en Mouvement en deux catégories :
- Traiter Avant : i.e. effectuer une segmentation statique en premier, puis associer les primitives des deux images pour obtenir la segmentation dynamique. Un certain nombre d'algorithmes de Mise en Correspondance ont été proposés dans la littérature pour l'association de primitives, minimisant la distance globale entre les attributs des primitives ;
- Traiter Après : i.e. obtenir directement le champ de déplacements (caractéristique mouvement) entre les deux images, modélisé ou non. Il est possible ensuite de regrouper (caractéristique statique) les pixels ayant un mouvement cohérent en objets mobiles.
Les méthodes de cette seconde catégorie peuvent être classées en deux types :
- locales, c'est-à-dire que le déplacement est calculé en chaque pixel, à partir des intensités de son voisinage ;
- globales, c'est-à-dire que l'on recherche une déformation globale de l'ensemble de l'image, à partir de la zone commune entre les deux images.
VII-D. Exemple de segmentations en mouvement▲
Nous allons donner quelques exemples des méthodes du pôle Traiter Après.
La méthode proposée par Horn & Shunk est locale. La figure n° 14 en présente les résultats(19).

F. Le Coat a utilisé une méthode globale, basée sur la Programmation Dynamique, entre bandes de lignes et de colonnes de l'image pour effectuer le recalage entre images cf. figure n° 15. Le raccordement correct des rails du chemin de fer atteste de la qualité du recalage.

Mathieu Pouzet (société EFFIDENCE) utilise une méthode hybride composée
- d'une méthode globale ESM- M Estimator, du pôle « Traiter Après »,
- mais également d'une méthode du pôle « Traiter Avant » d'association de points d'intérêt de Harris, mise en œuvre en secours lors de l'échec de la méthode précédente en cas de mouvement très important de la caméra,
le tout implanté de manière pyramidale, ainsi que d'une modélisation affine de la déformation pour extraire une information dense de mouvement. L'intérêt de l'hybridation est d'augmenter le domaine d'applications de la méthode globale, ce qui est nécessaire pour la réalisation d'un produit industriel.
Cette méthode est à la base de plusieurs applications proposée par la société :
- la Stabilisation d'images, permettant de s'affranchir des vibrations de la caméra ;
- la Création de panoramas (cf. figure n° 16) à partir d'un certain nombre d'images ;
- la Compensation du mouvement de la caméra pour la Détection de Cibles en Mouvement à partir d'une caméra en mouvement (cf. figure n° 17) ;
- la Création d'un arrière-plan dépourvu de cibles en mouvement (cf. figure n° 18).


Dans l'application de Surveillance de Routes ou d'Autoroutes à l'aide de Drones Aériens, la caméra est montée sur un drone et par conséquent peut subir des mouvements importants d'une image à l'autre. Compte tenu de l'altitude, l'hypothèse de la Transformation Affine est validée. La difficulté majeure est la détection et le suivi de petites cibles (taille 3 x 3) animés d'un petit mouvement (1 pixel/image), en présence d'un mouvement important de la caméra. Dans ce cas, la précision du recalage, qui compense le mouvement, est un élément fondamental.

La Corrélation est un principe simple et bien connu. Dans le cadre du PEA TAROT(20), nous avons proposé un système de poursuite basé sur corrélation permettant de réaliser deux types de missions en Autonomie Ajustable(21):
- le Suivi de Véhicules ;
- le Ralliement d'Amers, i.e. diriger un robot dans la direction d'un élément de la scène : arbre, bosquet, clocher, château d'eau ; etc.
La figure n° 19 présente les résultats obtenus sur une séquence de tests, dans le cadre du ralliement d'amers. L'opérateur présente l'amer au Système de Poursuite, en le détourant. Le rôle du système de vision est ensuite de suivre l'amer durant toute la séquence d'images.

Nous avons ensuite mis au point une procédure automatique de Détection d'Amers, en prenant pour hypothèse qu'un amer est une marque distinctive de taille importante au-dessus de la ligne d'horizon. La figure n° 20 présente des résultats obtenus avec un arbre et un château d'eau.

VIII. Profondeur/3D▲
Le but de cette segmentation est d'obtenir une information 3D de la scène notamment des objets la composant. L'être humain a deux yeux, et nous voyons, pour la plupart d'entre nous(22), le relief par la fusion effectuée par notre cerveau entre les images de nos deux yeux.
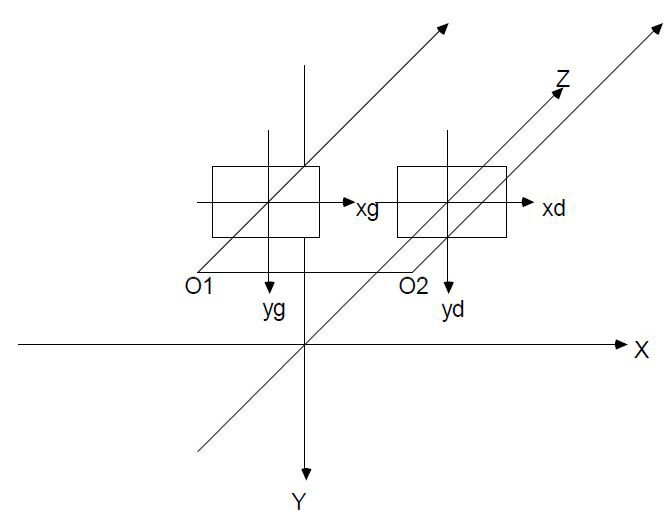
L'image de nous-même étant notre première source d'inspiration, il est logique que les premières études en matière de Stéréo vision (ou Vision en Trois Dimensions) utilisent comme support physique deux caméras montées sur un banc de vision stéréoscopique binoculaire avec une Géométrie Rectifiée c'est-à-dire où les deux axes optiques des caméras sont parallèles, comme nos deux yeux.
Outre l'aspect anthropomorphique, le banc à géométrie rectifiée a l'avantage de simplifier les équations permettant :
- la recherche des points homologues dans les deux images (Pg(xg,yg) de l'image gauche, et Pd(xd,yd) de l'image droite) provenant du même point P(x,y,z) de la scène 3D. Ils sont tout simplement situés sur la même ligne dans les deux images : soit y_g = y_d ;
- le calcul de la distance. Le point Pg de l'image gauche est plus à droite que le point P_d de l'image droite(23) : xg > xd. La disparité d = xg - xd est positive, et inversement proportionnelle à la distance z du point 3D de la scène P(x,y,z), au banc stéréoscopique. Le coefficient de proportionnalité dépend des paramètres du banc de vision stéréoscopique binoculaire et des deux caméras identiques.
La figure n° 21 présente les divers repères d'un tel banc : liés au banc, et liés aux caméras.
Des bancs de vision stéréoscopique binoculaire (à deux caméras) à géométrie quelconque, ainsi que triloculaire (à trois caméras) à double géométrie rectifiée (en forme de « L ») et à géométrie quelconque ont été ensuite proposés dans la littérature.
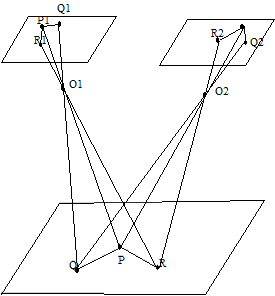
M.Hermann, et T. Kanade ont effectué en 1984 la Reconstruction 3D de scènes urbaines composées essentiellement de bâtiments avec toits en terrasse, à partir d'images aériennes. Pour ce faire, ils utilisent comme primitives images les jonctions de segments supposées être les projections dans les images des sommets de bâtiments, cf. figure n° 22(24). Bien évidemment, une seule caméra, montée sur avion, est utilisée. Elle prend deux images à un intervalle de temps connu, la vitesse et l'altitude de l'avion étant constantes et connues au cours de la prise de vues.
Depuis, les techniques ont évolué. On parle de Vues Multiples, d'Odométrie Visuelle : le robot quantifie son déplacement grâce à la vision, et même de SLAM(25) Visuel où le robot cartographie son environnement tout en se localisant à l'intérieur de celui-ci.
IX. Couleur▲
IX-A. Primitives couleur▲
Le monde est en couleur, nous le voyons comme tel avec nos yeux et nos caméras. Il est donc logique d'effectuer des traitements sur des images couleur (cf. figures n° 23 et 24).

Le principe de l'adaptation d'une segmentation d'image en N&B à une segmentation d'image en couleurs est simple. En effet pour une segmentation statique, on recherche les propriétés suivantes :
- pour les primitives points d'intérêt ou contours : les différences locales ;
- pour les primitives régions : l'homogénéité globale.
Le principe de l'adaptation des propriétés du niveau de gris à la couleur consiste à effectuer :
- pour les différences locales : un « OU LOGIQUE » entre les différences locales de chacun des plans couleurs ou spectraux ;
- pour l'homogénéité globale : un « ET LOGIQUE » entre les homogénéités globales de chacun des plans couleurs ou spectraux.
Ce principe est très simple à mettre en œuvre pour l'imagerie RVB où les trois plans spectraux sont parfaitement similaires, mais plus complexe dans les espaces couleurs YUV et Perceptifs où les divers plans représentent des grandeurs physiquement différentes. Il en est de même en imagerie multispectrale.
IX-B. Espaces perceptifs▲
Bien que nos yeux détectent les couleurs à partir de récepteurs en forme de cônes sensibles à différentes longueurs d'onde
- courtes : 420 nm, correspondant au bleu,
- moyennes : 530 nm, correspondant au vert,
- longues : 560 nm, correspondant au rouge,
notre cerveau fait que nous percevons les couleurs plutôt sous la forme de :
- Luminance, c'est-à-dire l'intensité lumineuse ;
- Teinte, i.e. la couleur : rouge, jaune, orange, vert, bleu, rose, violet…
- Saturation, i.e. le côté plus ou moins « délavé » : pâle ou vif.
Les chercheurs se sont inspirés de notre perception pour proposer un certain nombre d'espaces colorimétriques dits « Perceptuels », c'est-à-dire des espaces dans lesquels la distance(26) entre les couleurs est plus proche de notre ressenti visuel que dans les espaces RVB et YUV.
Thomas Costis(27) a montré que la reconnaissance automatique des couleurs est nettement moins sensible aux conditions d'illumination, c'est-à-dire aux variations d'intensité lumineuse dans les espaces perceptifs que dans les espaces RVB et YUV.
Un tel résultat est important. En effet, supposons que l'on cherche à détecter et à identifier les panneaux de signalisation routière. La forme ne suffit pas. Les panneaux signalant une autoroute sont sur fond bleu, ceux signalant un itinéraire bis sur fond vert, et ceux signalant des travaux sur fond orange… La distinction des couleurs (notamment vert/bleu) doit s'effectuer quelle que soit l'intensité lumineuse : d'un temps gris et pluvieux au soleil radieux.
IX-C. De la couleur au multispectral▲
Pour des applications, notamment du domaine militaire, l'imagerie couleur ne suffit pas. En effet, en le peignant aux couleurs de son environnement un véhicule blindé devient camouflé et difficilement détectable. Si celui-ci se déplace, propulsé par un moteur thermique, il chauffe et devient alors plus chaud que son environnement(28), et de ce fait détectable en imagerie IR. D'où l'idée de combiner les informations complémentaires venant des deux imageries : visible et infrarouge thermique.
Dans le cadre d'applications aériennes à plus haute altitude, le visible comme l'infrarouge sont mis en défaut par la couverture nuageuse, alors que le radar, passant à travers les nuages, permet toujours de récupérer de l'information : d'où l'idée de fusionner l'information provenant de multiples sources colocalisées ou non : Visible/IR/Radar.
Nous avons réalisé une étude en matière de segmentation multispectrale : Visible/IR/Radar, dans le cas d'imageurs colocalisés, avec des images Registrées, c'est-à-dire recalées et à même résolution : chaque pixel voit la même portion de la scène dans les diverses bandes spectrales.
X. Conclusion▲
Nous avons présenté succinctement dans cet article les différentes segmentations : en contours, en régions, en mouvement, en profondeur et en couleur qui permettent d'extraire les informations d'une image ou d'une séquence d'images. Les résultats présentés sont extraits d'applications que nous avons réalisées.
Dans le prochain article, le quatrième de la série, intitulé « Première Chaîne Complète de Segmentation » nous présenterons en détail les algorithmes de seuillage, de traitements morphologiques sur images binaires, et enfin de segmentation en composantes connexes, et proposerons une application au contrôle qualité.
N'hésitez pas à donner votre avis sur ce cours sur le forum d'entraide Traitement d'images : 20 commentaires ![]() .
.